Decoding the Temporal Representation of Facial Expression in Face-selective Regions
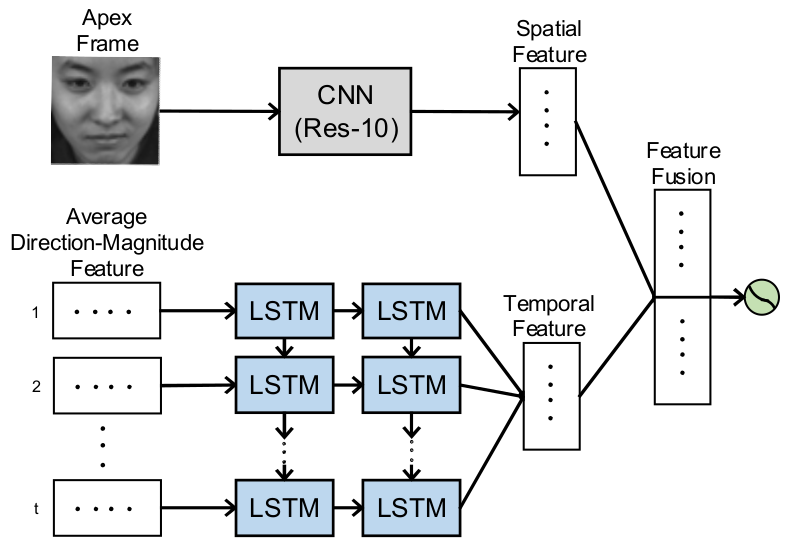
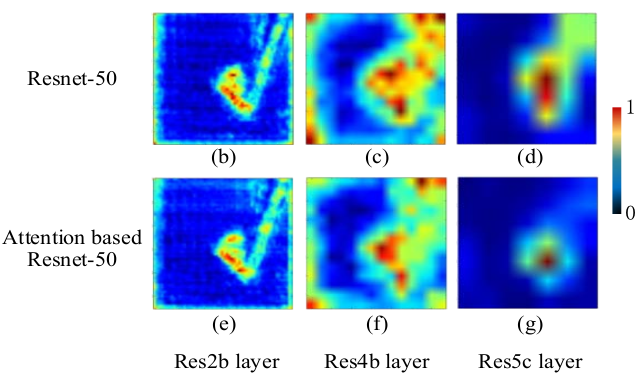
The ability of humans to discern facial expressions in a timely manner typically relies on distributed face-selective regions for rapid neural computations. To study the time course in regions of interest for this process, we used magnetoencephalography (MEG) to measure neural responses participants viewed facial expressions depicting seven types of emotions (happiness, sadness, anger, disgust, fear, surprise, and neutral). Analysis of the time-resolved decoding of neural responses in face-selective sources within the inferior parietal cortex (IP-faces), lateral occipital cortex (LO-faces), fusiform gyrus (FG-faces), and posterior superior temporal sulcus (pSTS-faces) revealed that facial expressions were successfully classified starting from ∼100 to 150 ms after stimulus onset. Interestingly, the LO-faces and IP-faces showed greater accuracy than FG-faces and pSTS-faces. To examine the nature of the information processed in these face-selective regions, we entered with facial expression stimuli into a convolutional neural network (CNN) to perform similarity analyses against human neural responses. The results showed that neural responses in the LO-faces and IP-faces, starting ∼100 ms after the stimuli, were more strongly correlated with deep representations of emotional categories than with image level information from the input images. Additionally, we observed a relationship between the behavioral performance and the neural responses in the LO-faces and IP-faces, but not in the FG-faces and lpSTS-faces. Together, these results provided a comprehensive picture of the time course and nature of information involved in facial expression discrimination across multiple face-selective regions, which advances our understanding of how the human brain processes facial expressions.
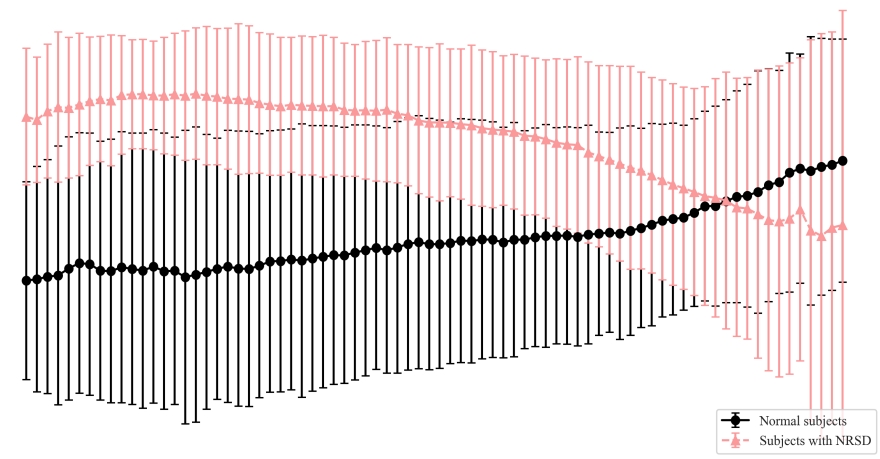 Identification of Non-Restorative Sleep Associated with Depression Using Ambulatory Electrocardiogram and Triaxial AccelerationIEEE Transactions on Biomedical Engineering
Identification of Non-Restorative Sleep Associated with Depression Using Ambulatory Electrocardiogram and Triaxial AccelerationIEEE Transactions on Biomedical Engineering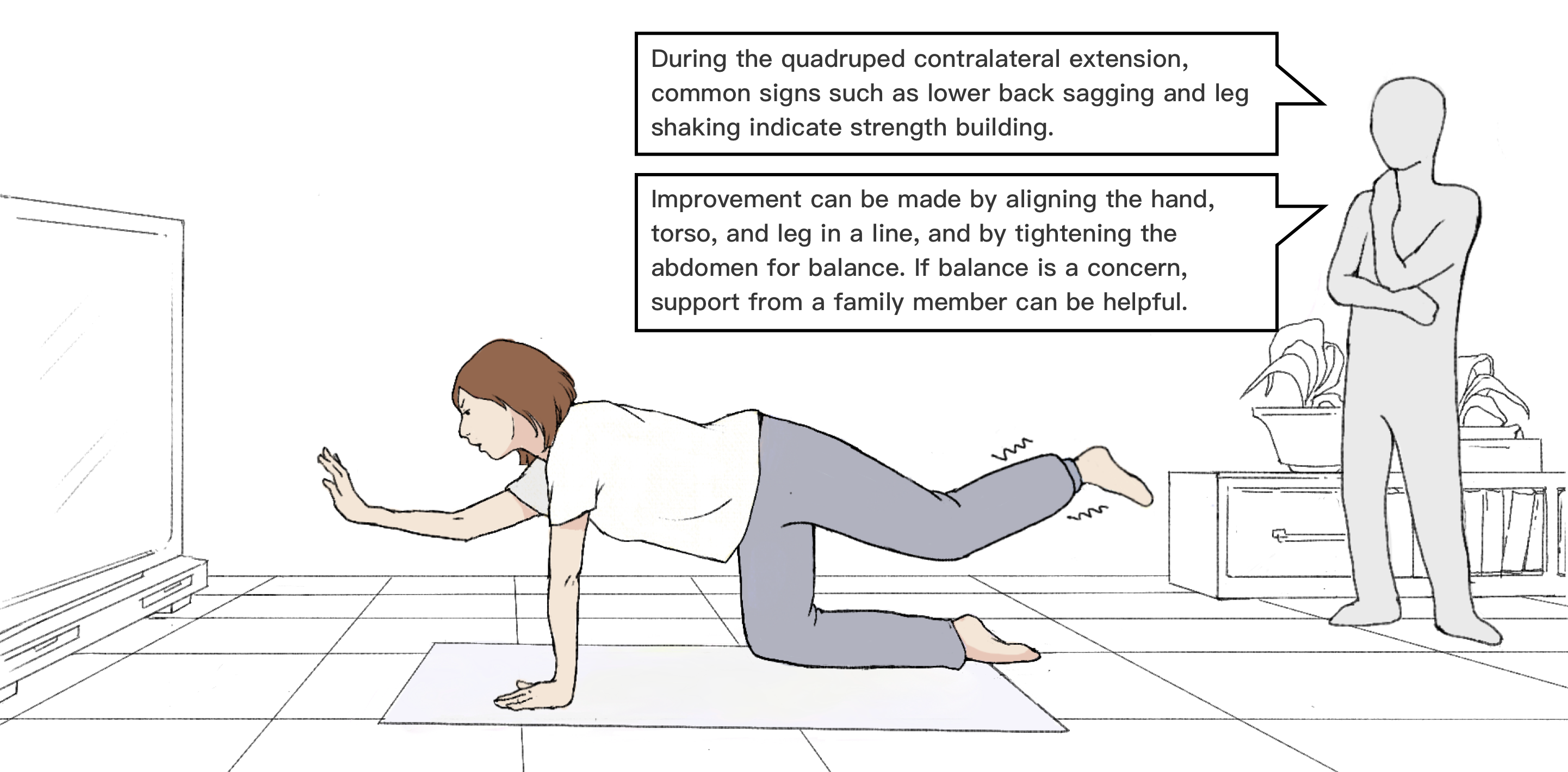 UbiPhysio: Support Daily Functioning, Fitness, and Rehabilitation with Action Understanding and Feedback in Natural LanguageProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)
UbiPhysio: Support Daily Functioning, Fitness, and Rehabilitation with Action Understanding and Feedback in Natural LanguageProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)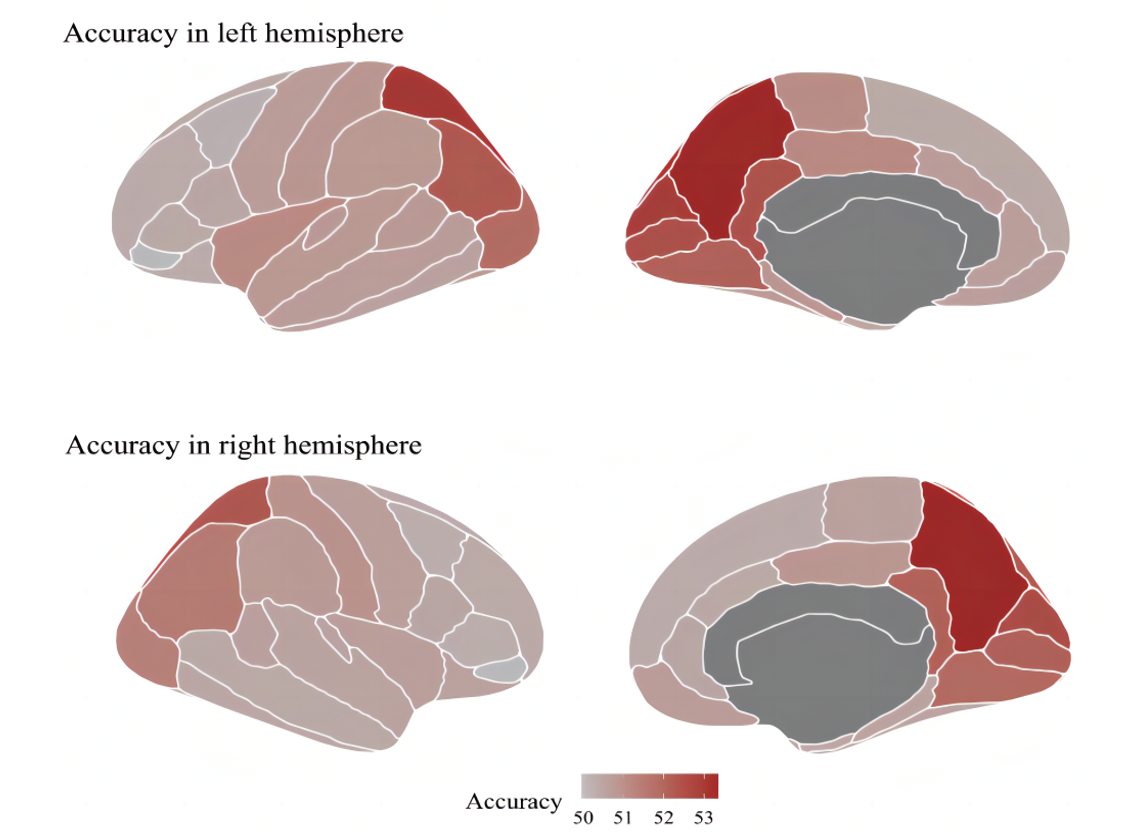 Decoding the Temporal Representation of Facial Expression in Face-selective RegionsNeuroimage
Decoding the Temporal Representation of Facial Expression in Face-selective RegionsNeuroimage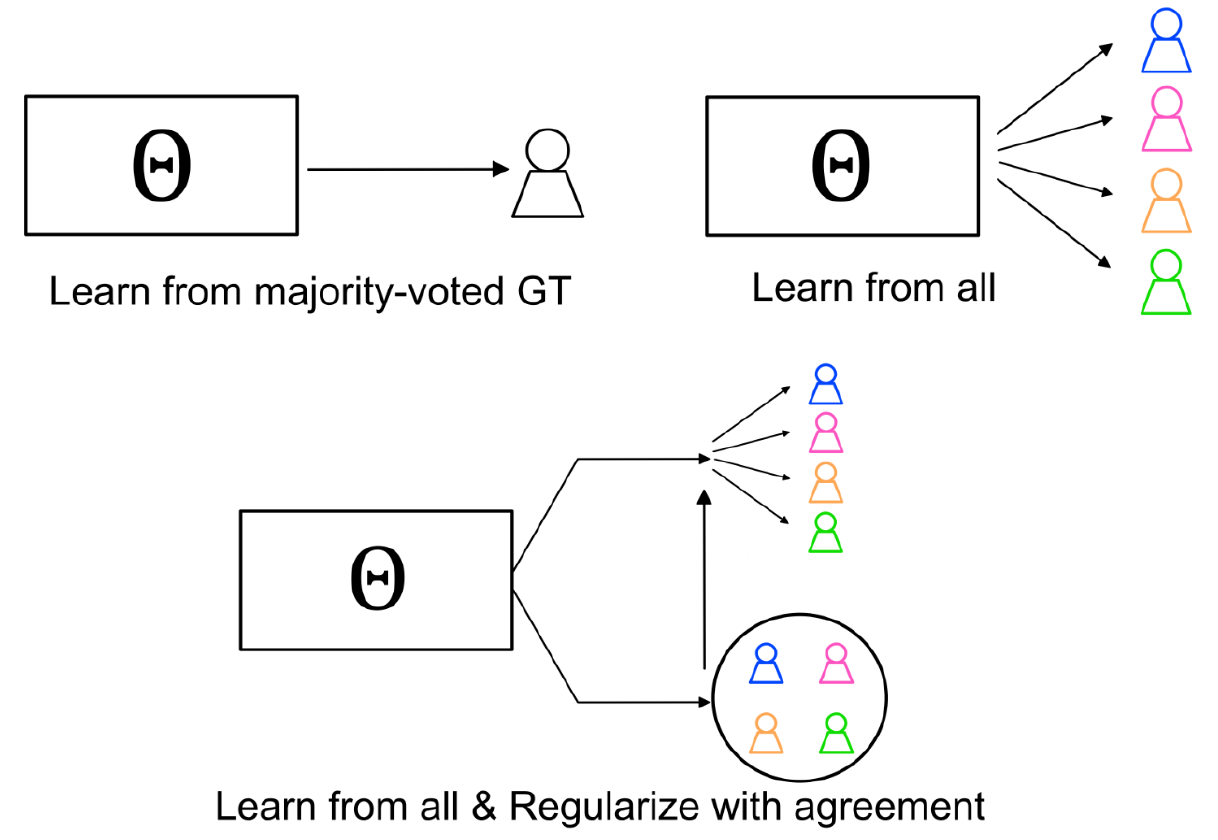 Learn2Agree: Fitting with Multiple Annotators without Objective Ground TruthTrustworthy Machine Learning for Healthcare Workshop at International Conference on Learning Representations (ICLR-TML4H)
Learn2Agree: Fitting with Multiple Annotators without Objective Ground TruthTrustworthy Machine Learning for Healthcare Workshop at International Conference on Learning Representations (ICLR-TML4H)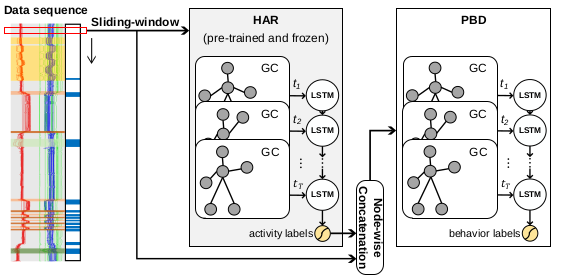 Leveraging Activity Recognition to Enable Protective Behavior Detection in Continuous DataProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)
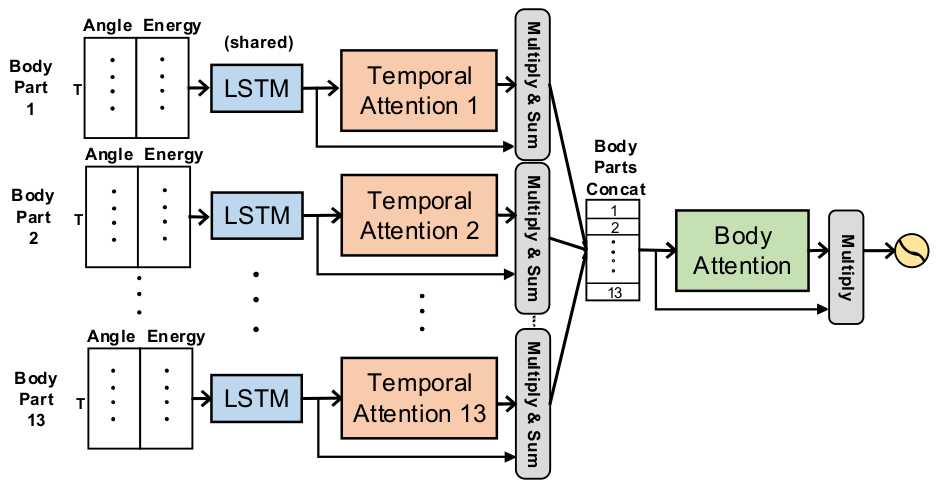
Leveraging Activity Recognition to Enable Protective Behavior Detection in Continuous DataProceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies (IMWUT)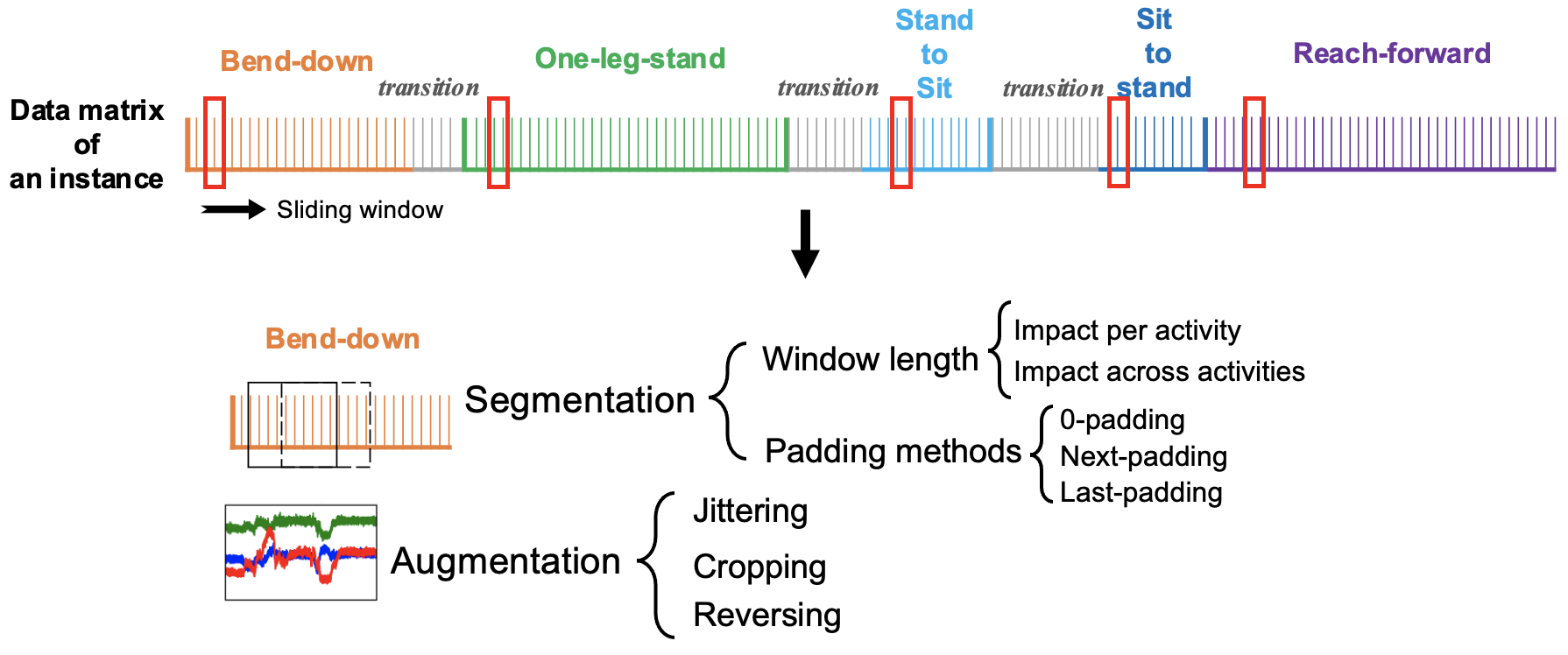 Chronic-Pain Protective Behavior Detection with Deep LearningACM Transactions on Computing for Healthcare
Chronic-Pain Protective Behavior Detection with Deep LearningACM Transactions on Computing for Healthcare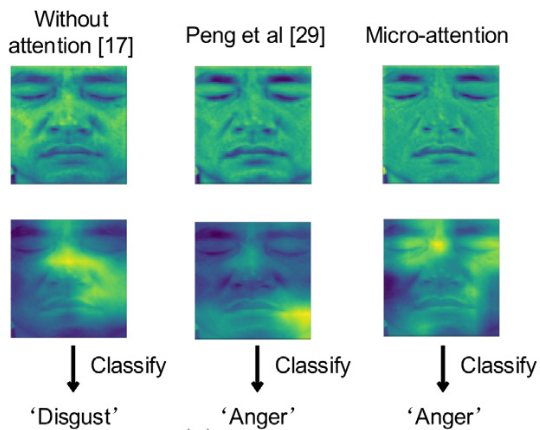
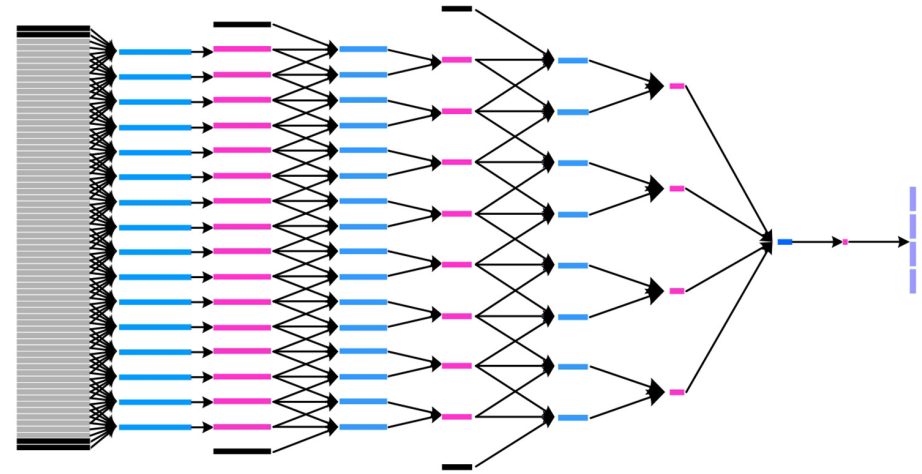
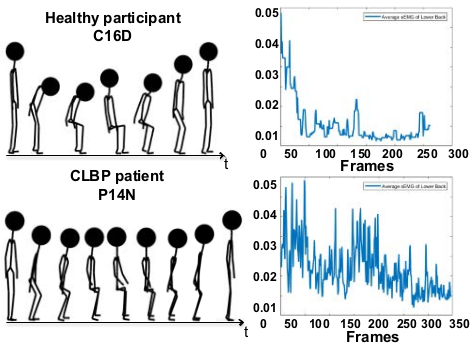 Recurrent Network based Automatic Detection of Chronic Pain Protective Behavior using Mocap and sEMG DataInternational Symposium on Wearable Computers (ISWC)
Recurrent Network based Automatic Detection of Chronic Pain Protective Behavior using Mocap and sEMG DataInternational Symposium on Wearable Computers (ISWC)